Running CephFS Load Balancer
Written by Michael SevillaIn this post we will set up CephFS and enable multiple active metadata servers. Then we will run a write-heavy metadata workload to show how CephFS balances metadata.
File system metadata workloads impose small and frequent requests on the underyling storage. This skewed workload makes it difficult to scale metadata IO in the same way that data read/write throughput scales. CephFS has strategies for helping metadata IO scale, such as decoupling metadata/data IO and providing mechanisms for detecting and migration metadata load to other servers. Metadata servers (MDSs) serve client requests and maintain the hierarchical file system namespace.
Running metadata load balancing on a single node may not produce realistic results because all the Ceph daemons run on the same node. For example, some balancers are dependent on CPU utilization (e.g., migrate metadata to another server when the CPU utilization reaches 30%). If you run everything on one node the CPU utilization will fluctuate wildly because the node is running object server daemons (OSDs), monitor daemons (MONs) and MDSs. If you are set on running on a single node, you can use vstart.sh – but you have been warned.
Set Up Ceph with Monitoring
Get a healthy Ceph cluster by following the instructions on the Ansible: Running Ceph
on a Cluster blog. Before you run the deploy script add
at least two more metadata servers and a Graphite server to site/hosts:
diff --git a/site/hosts b/site/hosts
index 664cf92..bfa6107 100644
--- a/site/hosts
+++ b/site/hosts
[mdss]
issdm-12 ansible_ssh_user=issdm
+issdm-15 ansible_ssh_user=issdm
+issdm-18 ansible_ssh_user=issdm
+[clients]
+issdm-24 ansible_ssh_user=issdm
+issdm-27 ansible_ssh_user=issdm
+
+[graphite]
+piha.soe.ucsc.edu ansible_ssh_user=issdm
Also set up monitoring for the metadata servers in site/ceph_monitor.yml:
diff --git a/site/ceph_monitor.yml b/site/ceph_monitor.yml
index 5372035..e13830c 100644
--- a/site/ceph_monitor.yml
+++ b/site/ceph_monitor.yml
@@ -5,7 +5,8 @@
roles:
- monitor/graphite
-- hosts: osds
+- hosts: mdss
become: True
roles:
- monitor/collectl
+ - ceph/ceph-stats
Be careful when selecting the polling interval for Graphite. We set ours to 10 seconds because if we increase the granularity (say to 1 second) then the CPU utilization of the Graphite server pins one CPU at 100%. To change the intervals check out the following parameters:
~/experiment$ cat site/group_vars/mdss | grep "args\|interval"
collectl_args: "-sC -i 10"
ceph_stats_interval: "10"
~/experiment$ cat site/group_vars/graphite_conf/storage-schemas.conf
[... snip ...]
[default_1sec_for_1day]
pattern = .*
retentions = 10s:1d
The variables in the group_vars/mdss configuration control how often the
metric collection daemons send metrics over the wire; the retentions variable
in storage-schemas.conf controls the timestamp granularity of the Graphite
database (called the WhisperDB). Just like the Ansible: Running Ceph on a
Cluster blog we start the Ceph cluster using:
./deploy.sh
Set Up CephFS
In this section we use three helper scripts to interact with our cluster. These scripts use Ansible version 2.1.2.0. Ansible deprecates features quickly and we have fought with version problems a lot in the past so we package Ansible in a Docker container. Docker alleviates these versioning headaches but requires a bunch of command line arguments so we wrap them in scripts:
-
ansible.sh: executes commands on nodes in thehostsfile -
ansible-playbook.sh: executes a lists of commands on hosts (i.e. playbooks) -
ceph-mds-daemon.sh: logs into each MDS and talks to the admin daemon socket
After running the deploy script the cluster should have 1 active metadata
server and 2 standby metadata servers in the fsmap section of the Ceph health
status. We can check with:
~/experiment$ ./ansible.sh mons -m shell -a "docker exec \`hostname\` ceph -s"
issdm-3 | SUCCESS | rc=0 >>
cluster e9570dd8-03ad-45f0-8a74-ec9b3bb7095f
health HEALTH_OK
monmap e1: 1 mons at {issdm-3=192.168.140.224:6789/0}
election epoch 3, quorum 0 issdm-3
fsmap e7: 1/1/1 up {0=issdm-12=up:active}, 2 up:standby
mgr no daemons active
osdmap e23: 9 osds: 9 up, 9 in
flags sortbitwise,require_jewel_osds,require_kraken_osds
pgmap v50: 1088 pgs, 3 pools, 2882 bytes data, 20 objects
91121 MB used, 1648 GB / 1737 GB avail
1088 active+clean
We can activate those 2 standby metadata servers using the cephfs.yml playbook:
~/experiment$ ./ansible-playbook.sh cephfs.yml
PLAY [mons[0]] *****************************************************************
TASK [setup] *******************************************************************
ok: [issdm-3]
TASK [setup mon convenience functions] *****************************************
ok: [issdm-3]
TASK [allow multiple active MDSs] **********************************************
changed: [issdm-3]
TASK [activate the standby MDSs] ***********************************************
changed: [issdm-3]
PLAY RECAP *********************************************************************
issdm-3 : ok=4 changed=2 unreachable=0 failed=0
Checking again we see 3 active metadata servers:
~/experiment$ ./ansible.sh mons -m shell -a "docker exec \`hostname\` ceph -s | grep fsmap"
issdm-3 | SUCCESS | rc=0 >>
fsmap e12: 3/3/5 up {0=issdm-12=up:active,1=issdm-18=up:active,2=issdm-15=up:active}
Note the order of the metadata servers – that is important for later. In our cluster issdm-12, issdm-18, and issdm-15 are MDS0, MDS1, and MDS2, respectively.
Running a Create-Heavy Workload
To quote the Mantle documentation:
As a pre-requisite, we assume you have installed mdtest or pulled the Docker image. We use mdtest because we need to generate enough load to get over the
MIN_OFFLOADthreshold that is arbitrarily set in the balancer. For example, this does not create enough metadata load:while true; do touch "/cephfs/blah-`date`" done
For context, MIN_OFFLOAD is a threshold in the CephFS metadata
balancer
that prevents thrashing. Thrashing is when metadata load is migrated too
frequently around the metadata cluster. In other words, MIN_OFFLOAD prevents
migrations triggered by transient spikes of metadata load.
Our workload creates many file creates in different directories. While a reasonable strategy for this workload is to have separate mount points backed by distinct file systems, we use one CephFS instance to show off the metadata migration mechanisms. To run the workload:
~/experiment$ ./ansible-playbook.sh --extra-vars "nfiles=100000" workloads/metawrites.yml
Looking at metawrites.yml we see that the playbook logs into every client and
starts running the metadata test in a container. We can verify this by checking
the containers that run on client nodes:
~/msevilla/experiment$ ./ansible.sh clients -a "docker ps"
issdm-24 | SUCCESS | rc=0 >>
IMAGE COMMAND NAMES
michaelsevilla/mdtest "/mdtest/mdtest -F -C" client
piha.soe.ucsc.edu:5000/ceph/daemon:master "/bin/bash -c 'ceph-f" cephfs
piha.soe.ucsc.edu:5000/ceph/daemon:master "/entrypoint.sh" issdm-24-osd-devsde
issdm-27 | SUCCESS | rc=0 >>
IMAGE COMMAND NAMES
michaelsevilla/mdtest "/mdtest/mdtest -F -C" client
piha.soe.ucsc.edu:5000/ceph/daemon:master "/bin/bash -c 'ceph-f" cephfs
piha.soe.ucsc.edu:5000/ceph/daemon:master "/entrypoint.sh" issdm-27-osd-devsde
Note that the cephfs container shares its mount with the client countainer. We also see an OSD running – our cluster is not big enough to dedicate standalone clients.
Good Balancing
While the job is running we can view the migrations in two ways. One way is to use Graphite. If you want to see how we made these graphs, check out the Baselining a Ceph Cluster blog. First we graph the # of processed requests over time (x axis is in minutes) – this shows the throughput of each metadata server.
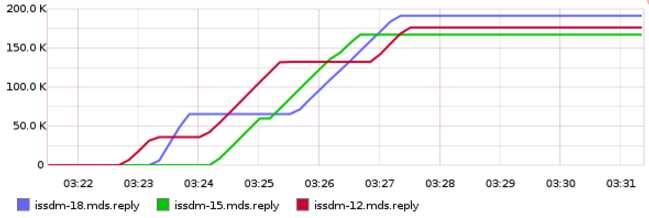
This graph is an example of good load balancing. Metadata load starts on MDS0 (issdm-12) at time 3:22, then at 3:23 all directories get migrated to MDS1 (issdm-18), and finally at time 3:24 one directory lands on MDS0 and one on MDS2 (issdm-15). At time 3:25:30 MDS0 sends load to MDS1 but the throughput remains the same.
The migration at 3:25:30 is problematic but not a terrible situation as we see a downtime of less than a minute. Next we look at a badly balanced namespace.
Bad Balancing
We ran the job again. This time we get different behavior:
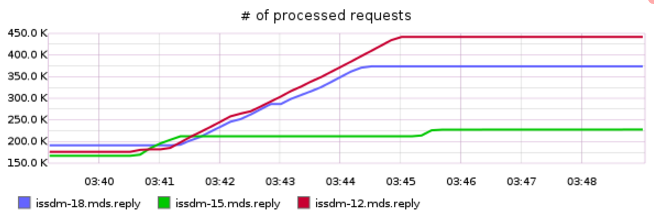
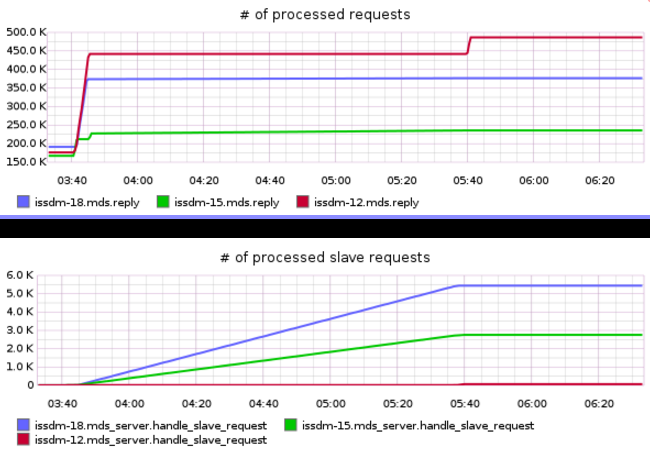
Again, we see the flurry of migrations between 3:40 and 3:42; then we see stable throughput with MDS0 and MDS1 shouldering most of the load until 3:45. At this time throughput flattens. To dig into this a little more we can look at slave requests and forwarded requests. Slave requests are incoming requests from another MDS and forwarded requests are outgoing requests to another MDS:
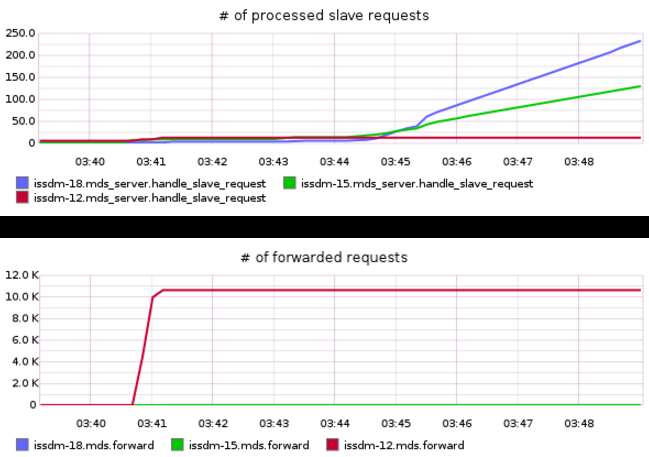
Now we see what the cluster is doing – throughput has stagnated and MDS0 has
started forwarding requests to MDS1 and MDS2. But why? We can investigate
using the CephFS get subtrees debugging tool:
~/xperiment$ ./ceph-mds-admin-daemon.sh "get subtrees | grep -B4 path | grep \"path\|is_auth\""
issdm-18 | SUCCESS | rc=0 >>
"is_auth": false,
"path": "",
"is_auth": true,
"path": "\/nfiles-100000-2016-11-08-19:22:40-issdm-24",
"is_auth": false,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-27",
"is_auth": true,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-27\/#test-dir.0",
"is_auth": false,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-27\/#test-dir.0\/mdtest_tree.0",
issdm-12 | SUCCESS | rc=0 >>
"is_auth": true,
"path": "",
"is_auth": false,
"path": "\/nfiles-100000-2016-11-08-19:22:40-issdm-24",
"is_auth": false,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-24",
"is_auth": false,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-27",
issdm-15 | SUCCESS | rc=0 >>
"is_auth": false,
"path": "",
"is_auth": true,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-27",
"is_auth": false,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-27\/#test-dir.0",
"is_auth": true,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-27\/#test-dir.0\/mdtest_tree.0",
"is_auth": true,
"path": "\/nfiles-100000-2016-11-08-19:40:31-issdm-24",
We have snipped out the CephFS Snapshot directories. The obscure directory names are from our workload generating tool but the above subtree dump indicates that the hierarchical file system namespace looks like this:
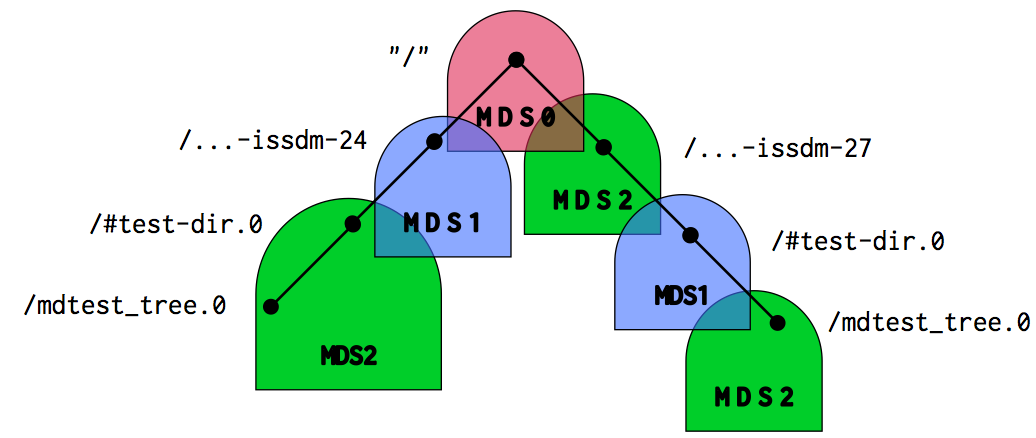
What a mess. We can see that the namespace is very fragmented, resulting in forwards and less overall throughput. CephFS uses dynamic subtree partitioning and here we show one of the drawbacks: making migration decisions is difficult (e.g., where to send load, how much to send, and how to break up the namespace).
Restoring Throughput
First we disable balancing.
~/experiment$ ./ceph-mds-admin-daemon.sh "config set mds_bal_interval -1"
issdm-18 | SUCCESS | rc=0 >>
{
"success": "mds_bal_interval = '-1' (unchangeable) "
}
issdm-12 | SUCCESS | rc=0 >>
{
"success": "mds_bal_interval = '-1' (unchangeable) "
}
issdm-15 | SUCCESS | rc=0 >>
{
"success": "mds_bal_interval = '-1' (unchangeable) "
}
Now migrate all trees back to the first metadata server; note that this will differ depending on how your namespace fragmented:
issdm@piha:~/msevilla/experiment$ ./ceph-mds-admin-daemon.sh "export dir nfiles-100000-2016-11-08-19:22:40-issdm-24 0"
issdm-18 | SUCCESS | rc=0 >>
{
"return_code": 0
}
issdm@piha:~/msevilla/experiment$ ./ceph-mds-admin-daemon.sh "export dir nfiles-100000-2016-11-08-19:40:31-issdm-27 0"
issdm-15 | SUCCESS | rc=0 >>
{
"return_code": 0
}
issdm@piha:~/msevilla/experiment$ ./ceph-mds-admin-daemon.sh "export dir nfiles-100000-2016-11-08-19:40:31-issdm-24 0"
issdm-15 | SUCCESS | rc=0 >>
{
"return_code": 0
}
issdm@piha:~/msevilla/experiment$ ./ceph-mds-admin-daemon.sh "export dir nfiles-100000-2016-11-08-19:40:31-issdm-24 0"
issdm-15 | SUCCESS | rc=0 >>
{
"return_code": 0
}
ssdm@piha:~/msevilla/experiment$ ./ceph-mds-admin-daemon.sh "export dir nfiles-100000-2016-11-08-19:40:31-issdm-27\/#test-dir.0 0"
issdm-18 | SUCCESS | rc=0 >>
{
"return_code": 0
}
issdm@piha:~/msevilla/experiment$ ./ceph-mds-admin-daemon.sh "export dir nfiles-100000-2016-11-08-19:40:31-issdm-27\/#test-dir.0\/mdtest_tree.0 0"
issdm-15 | SUCCESS | rc=0 >>
{
"return_code": 0
}
We should verify that the directories coalesced in the namespace:
~/experiment$ ./ceph-mds-admin-daemon.sh "get subtrees | grep -B4 path | grep \"path\|is_auth\""
issdm-18 | SUCCESS | rc=0 >>
"is_auth": true,
"path": "~mds1",
issdm-12 | SUCCESS | rc=0 >>
"is_auth": true,
"path": "",
issdm-15 | SUCCESS | rc=0 >>
"is_auth": false,
"path": "",
This subtree dump looks a lot different. Each subtree got merged back into its parent directory and now MDS0 owns the entire namspace. This looks like it fixed the throughput stagnation at time 5:40:
To understand why migration decisions are made we can look at the logs:
issdm@issdm-12:~$ docker logs ceph-issdm-12-mds 2>&1 | grep nicely
2016-11-08 19:23:17.368483 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.1 [dir 10000000000 /nfiles-100000-2016-11-08-19:22:40-issdm-24/ [2,head] auth pv=77 v=75 cv=0/0 ap=1+280+281 state=1610612738|complete f(v0 m2016-11-08 19:22:48.817770 1=0+1) n(v3 rc2016-11-08 19:23:16.065854 16548=16546+2) hs=1+0,ss=0+0 dirty=1 | child=1 dirty=1 authpin=1 0x7fa75bb80520]
2016-11-08 19:23:17.368660 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.1 [dir 100000003e9 /nfiles-100000-2016-11-08-19:22:40-issdm-27/ [2,head] auth pv=77 v=75 cv=0/0 ap=1+266+267 state=1610612738|complete f(v0 m2016-11-08 19:22:48.982327 1=0+1) n(v3 rc2016-11-08 19:23:16.024052 16547=16545+2) hs=1+0,ss=0+0 dirty=1 | child=1 dirty=1 authpin=1 0x7fa75bb80e68]
2016-11-08 19:24:17.529501 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.2 [dir 100000003e9 /nfiles-100000-2016-11-08-19:22:40-issdm-27/ [2,head] auth pv=170 v=168 cv=0/0 ap=1+518+519 state=1610612738|complete f(v0 m2016-11-08 19:22:48.982327 1=0+1) n(v10 rc2016-11-08 19:24:15.648997 28915=28913+2) hs=1+0,ss=0+0 dirty=1 | child=1 frozen=0 subtree=0 importing=0 replicated=0 dirty=1 waiter=0 authpin=1 tempexporting=0 0x7fa75bb80e68]
2016-11-08 19:24:37.492148 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.1 [dir 10000000000 /nfiles-100000-2016-11-08-19:22:40-issdm-24/ [2,head] auth{1=1} pv=212 v=209 cv=0/0 ap=2+100+101 state=1610612738|complete f(v0 m2016-11-08 19:22:48.817770 1=0+1) n(v12 rc2016-11-08 19:24:36.670310 36664=36662+2) hs=1+0,ss=0+0 dirty=1 | child=1 frozen=0 subtree=0 importing=0 replicated=1 dirty=1 waiter=0 authpin=1 tempexporting=0 0x7fa75bb80520]
2016-11-08 19:24:47.491332 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.1 [dir 10000000000 /nfiles-100000-2016-11-08-19:22:40-issdm-24/ [2,head] auth{1=1} pv=235 v=232 cv=0/0 ap=2+41+42 state=1610612738|complete f(v0 m2016-11-08 19:22:48.817770 1=0+1) n(v13 rc2016-11-08 19:24:46.681390 40895=40893+2) hs=1+0,ss=0+0 dirty=1 | child=1 frozen=0 subtree=0 importing=0 replicated=1 dirty=1 waiter=0 authpin=1 tempexporting=0 0x7fa75bb80520]
2016-11-08 19:25:27.492420 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.1 [dir 10000000000 /nfiles-100000-2016-11-08-19:22:40-issdm-24/ [2,head] auth{1=1} pv=328 v=325 cv=0/0 ap=2+40+41 state=1610612738|complete f(v0 m2016-11-08 19:22:48.817770 1=0+1) n(v17 rc2016-11-08 19:25:26.890278 57901=57899+2) hs=1+0,ss=0+0 dirty=1 | child=1 frozen=0 subtree=0 importing=0 replicated=1 dirty=1 waiter=0 authpin=1 tempexporting=0 0x7fa75bb80520]
2016-11-08 19:40:43.958632 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.2 [dir 1000001047e /nfiles-100000-2016-11-08-19:40:31-issdm-24/ [2,head] auth pv=13 v=11 cv=0/0 ap=1+561+562 state=1610612738|complete f(v0 m2016-11-08 19:40:39.689282 1=0+1) n(v0 rc2016-11-08 19:40:42.692915 2077=2075+2) hs=1+0,ss=0+0 dirty=1 | child=1 dirty=1 authpin=1 0x7fa75bb80b50]
2016-11-08 19:40:43.958778 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.2 [dir 10000013cbe /nfiles-100000-2016-11-08-19:40:31-issdm-27/ [2,head] auth v=11 cv=0/0 ap=0+560+561 state=1610612738|complete f(v0 m2016-11-08 19:40:39.872170 1=0+1) n(v0 rc2016-11-08 19:40:43.017250 1976=1974+2) hs=1+0,ss=0+0 dirty=1 | child=1 dirty=1 authpin=0 0x7fa75bb81de0]
2016-11-08 19:42:43.918809 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.2 [dir 1000001047e /nfiles-100000-2016-11-08-19:40:31-issdm-24/ [2,head] auth{2=1} pv=254 v=252 cv=0/0 ap=1+273+274 state=1610612738|complete f(v0 m2016-11-08 19:40:39.689282 1=0+1) n(v11 rc2016-11-08 19:42:42.725309 40465=40463+2) hs=1+0,ss=0+0 dirty=1 | child=1 frozen=0 subtree=0 importing=0 replicated=1 dirty=1 waiter=0 authpin=1 tempexporting=0 0x7fa75bb80b50]
2016-11-08 19:45:03.888950 7fa74ac2e700 0 mds.0.migrator nicely exporting to mds.2 [dir 1000001047e /nfiles-100000-2016-11-08-19:40:31-issdm-24/ [2,head] auth{2=1} pv=574 v=569 cv=332/332 ap=3+351+352 state=1610612738|complete f(v0 m2016-11-08 19:40:39.689282 1=0+1) n(v23 rc2016-11-08 19:45:02.126897 94200=94198+2) hs=1+0,ss=0+0 dirty=1 | child=1 frozen=0 subtree=0 importing=0 replicated=1 dirty=1 waiter=0 authpin=1 tempexporting=0 0x7fa75bb80b50]
We can see why directories are sent to different metadata servers. The namespace partitioning falls into a bad layout for throughput and stays there because when requests start getting forwarded the perceived “metadata load” drops. With low metadata load migration is not necessary. The problems with the decision making is decribed in more depth in the Mantle paper.
Conclusion
There are good and bad balancing configurations. A good configuration has good throughput; a bad configuration has low throughput because the hierarchical file system namespace is partitioned across the cluster poorly. Furthermore, the cluster cannot get out of the bad state because the metadata load is not high enough to trigger migrations.
Jekyll theme inspired by researcher
Don't click on this easter egg:
